Um dos meus tickets naquela semana era aparentemente simples: exportar uns dados pra um arquivo CSV. Simples, não?
A ideia inicial era:
- Criar um comando no Django que fizesse a busca no banco, exportasse pra um CSV e fizesse o upload dele no nosso S3
- Esse CSV só precisava ter dois campos: um ID e o corpo do email em HTML
Problema #1: buscando no banco
Na teoria tudo parecia correr perfeitamente bem e fácil. Até que eu descobri: nós tínhamos 3 MILHÕES de emails e o corpo do HTML estava dentro de um campo JSON. O HTML era enorme em boa parte dos casos. Fazendo uma busca no banco, o maior deles tem 2.370.814 caracteres.
Ao fazer a busca no nosso banco, utilizando o ORM do Django, iterar sobre os dados pra inserir no CSV já não era viável. Os 3M eram carregados em memória, trazendo aquele belo Error R14 (Memory quota exceeded) no Heroku. E isso eu só pude ver em Staging, o único lugar onde nós temos os e-mails da empresa no banco. Por conta do tamanho do dump, evitamos ter dados como esses localmente.
Problema #2: otimizando a busca
A query estava gigante e carregando tudo em memória. Simples resolver isso: iterator nele! A query até que não demorava pra carregar. Com o uso de geradores ficou ainda mais rápida. Entretanto, teria que iterar nos 3M de todo jeito. Se algo desse errado, teríamos que exportar tudo de novo. Sem falar que 100GB de um CSV pra transitar por aí não era muito viável (não que CSV seja confiável pra alguma coisa…).
Problema #3: otimizando a busca - parte II
Para resolver esse drama com a quantidade de memória e ter a possibilidade de retomar caso algo desse errado, dividi em chunks (partes) de 500.000 emails, decidindo exportar em CSVs distintos mesmo. Caso fosse necessário interromper algum, só era necessário passar o número do chunk como parâmetro. Sucesso. Mas ainda estava demorando pra escrever os CSVs. Para dar uma ideia, os 3M levaram 3 horas e 08 minutos para serem escritos, usando uma máquina com 14GB de RAM.
Problema #4: otimizando a escrita
A essa altura do campeonato, já era sabido que a escrita do CSV era um gargalo. Eu estava sem grandes ideias até que eu lembrei de uma palestra maravilhosa, dada pelo Gustavo Pantuza na Python Nordeste 2017, sobre como escrever módulos C em código Python. Primeiro, eu tentei usar Golang mas não rolou. Depois de bater um papo com o Pantuza, descobri que teria que usar C de todo jeito pra fazer o meio de campo. Resolvi “”“reduzir a complexidade”“” escrevendo em C apenas.
Tudo bem que eu passei algumas boas horas para colocar as duas linguagens para conversar. Apesar de ser relativamente fácil, essa foi a minha primeira extensão de um módulo C em Python e eu queria que: dada uma lista de dicionários, escreva um CSV, que nem o DictWriter do Python. Ou seja: teria que dar suporte a lista de dicionários no código C.
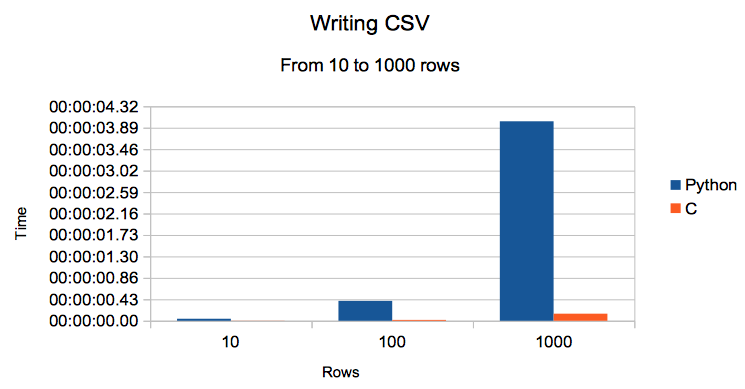
Bem, tudo funcionando, hora de fazer os primeiros testes. Gerei dados aleatórios com um campo pequeno, representando o ID, e outro maior, com 200.000 caracteres, representando o HTML Body. Gerei amostras com 10, 100, 1000 e 1.000.000 de linhas (lembrando: listas de dicionários). E o resultado foi absurdo:
| Número de Linhas | Python | C |
|---|---|---|
| 10 | 0:00:00.040122 | 0:00:00.001918 |
| 100 | 0:00:00.400158 | 0:00:00.016712 |
| 1000 | 0:00:04.018013 | 0:00:00.142304 |
| 1000000 | 1:08:38.468106 | 0:06:41.071689 |
É isso mesmo: pra escrever 1 milhão de registros, com Python, levou 1 hora e 8 minutos. Em C, levou quase 10% do tempo: 06 minutos! 😱🤯
Adicionei esse gráfico aqui até 1.000 linhas porquê com 1 milhão não dava pra ver o resultado dos outros.
Você pode ver o código dessa brincadeira aqui. Se você está interessada em brincar com isso também, não deixe de dar uma olhada nos slides do Pantuza e no tutorial que ele escreveu sobre o assunto.
Divirta-se!
comments powered by Disqus