O Diário Oficial é uma publicação oficial onde a cidade, o estado ou a União (governo federal) deve comunicar para a população todas as decisões e informações relevantes, como contratos firmados, pessoas aprovadas em um concurso ou alterações no orçamento. Podemos dizer que os Diários Oficiais são uma das ferramentas mais antigas na transparência - o primeiro Diário Oficial foi publicado em 1808!
Corta para 2020: onde estamos com os diários hoje? Infelizmente, não existe um formato padrão para os Diários Oficiais; cada lugar tem autonomia para publicar no formato que quiser: HTML, PDF em texto, PDF em imagem… E também com a estrutura que quiser. Agora imagine o que poderíamos fazer tendo informações das mais de 5 mil cidades do Brasil, de maneira buscável e estruturada? Essa é a proposta do Querido Diário! ❤️
O Querido Diário é um projeto de código aberto onde qualquer pessoa pode contribuir. Você também pode contribuir com esse projeto fantástico e acelerar o seu desenvolvimento através da campanha de financiamento coletivo no Catarse. Mas, caso você queira contribuir com código, esse texto é para você. Vem comigo!
Quero contribuir - por onde eu começo?#
Pré-requisitos para rodar o projeto: ter o Git e, no mínimo, o Python 3.6 instalados na sua máquina.
Primeiro, você precisa ter conhecimentos de Git para modificar o código do projeto. Caso você ainda não tenha contribuído para nenhum projeto de código aberto, pode começar criando uma conta no Github e vendo esse material que a galera do PUG-PE criou.
Tudo certo com o git: ✅. Você não precisa se aprofundar muito pois o básico é o suficiente para começar. A galera do Querido Diário preparou uma documentação bacana e uns atalhos para a gente contribuir sem medo. Vamos nessa?
Spiders?🕷#
Calma, antes de começarmos mesmo, precisamos falar sobre spiders. Você vai ouvir muito essa nomenclatura no projeto, por isso é importante entender do que se trata.
Lembra que falamos que os diários não são estruturados e quem vem de fontes diferentes pois cada lugar tem autonomia para publicar como e onde quiser? Pois é, isso traz um grande desafio tecnológico para o projeto. Precisamos escrever um programa que raspe os dados dos sites de cada cidade e transforme-os em um formato que seja comum a todos. Esse programa que raspa dados de um site é chamado de spider (aranha em inglês). Essa “aranha” vai passeando pelas estruturas HTML que nós especificamos e coleta as informações que queremos. Particularmente, é uma das coisas que eu acho mais legais de fazer enquanto programadora. :)
Não vou mentir para vocês: no início pode parecer meio esquisito, principalmente se a estrutura das páginas do site não forem boas. Mas sabendo um tico de HTML já é o suficiente para você entender melhor. Quer uma dica? Se você nunca fez isso, vá até a página do Diário Oficial da sua cidade e clique com o botão direito do mouse. Clicou? Você deve ver a opção “Ver código fonte da página”. Viu quanta coisa tem? Pois é. Visualizar diretamente o código fonte da página é a maneira mais fiel de conferir os elementos; nem sempre a ferramenta que vamos utilizar irá renderizar o HTML da mesma forma e precisamos saber como investigar possíveis discrepâncias.
Vamos usar uma opção que nos ajude a encontrar o elemento HTML exato. Procure informações que você já tinha visto na página, como a edição do Diário. Clique com o botão direito do mouse e então na opção “Inspecionar “. Uma janela será aberta indicando o elemento correto. Clicou? Certo mas como transformar isso em código? Calma lá, vamos a continuação dessa dica. Ainda na janela do inspecionador, clique com o botão direito no elemento HTML que você havia escolhido e na opção “Copiar” você pode ver diversas opções: Copiar “CSS Path”, “Copiar XPath”…
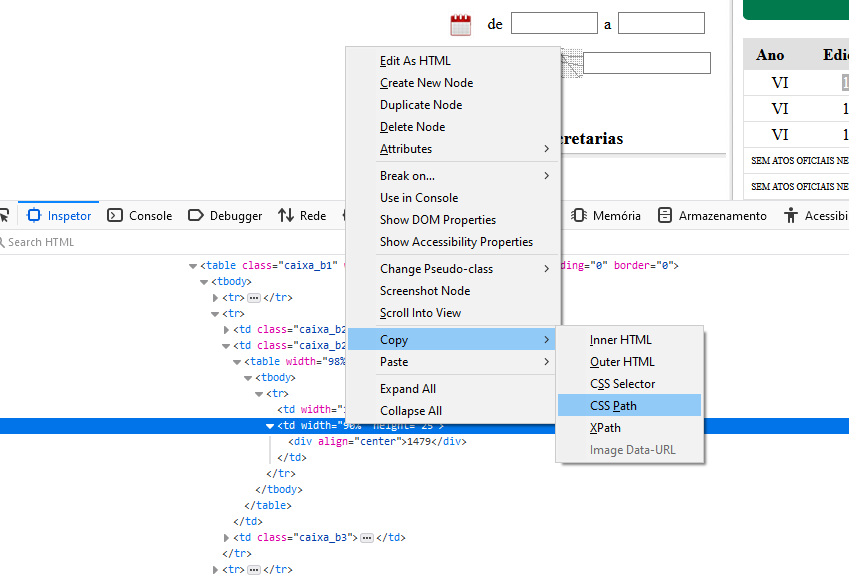
No exemplo, o Diário Oficial da cidade de Feira de Santana - BA.
Esses seletores serão úteis ao escrever um spider pois serão o caminho exato para os elementos que precisamos!
Scrapy#
Agora que você já tem uma noção de como descobrir o elemento na página já pode partir para a próxima etapa: o tutorial do Scrapy (em inglês). O Scrapy é um framework poderoso que serve para facilitar a raspagem de dados. O tutorial do Scrapy é uma das fontes mais confiáveis para aprender como criar spiders e como raspar dados da web. Se possível, leia o tutorial e vá executando o código. Após passar pelo tutorial você estará mais que pronta para criar seus próprios spiders no Querido Diário.
Antes de codar…#
Caramba, quanto rodeio, hein? :) Calma, tudo isso é para que você caminhe pelo projeto da melhor maneira possível. Digamos que você já tem tudo configurado e pronto para a ação. Isso é ótimo! Mas agora vem uma parte importante: já sabe qual a cidade você quer raspar dados? Se sim ou se não, cheque os passos:
Verifique se a cidade que você quer colaborar já está no censo; se não estiver, é legal adicionar lá. Ao ajudar no mapeamento você também vai coletar informações importantes para a sua contribuição!
Depois de checar o censo, verifique se já existe um spider no repositório: https://github.com/okfn-brasil/querido-diario/tree/main/data_collection/gazette/spiders ou aguardando merge: https://github.com/okfn-brasil/querido-diario/pulls
Não existe ainda? Yay! Crie uma nova issue para sinalizar que você trabalhará nela (exemplo: okfn-brasil/querido-diario: Issue #299)
Seguindo esses passos, imaginamos que você encontrou uma das 5.070 cidades que ainda não tem um spider pronto. Uhuu!
Hora do show#
No repositório do Querido Diário você encontrará um guia de contribuição (em inglês). Lá tem informação atualizada de como fazer a configuração inicial do projeto e explorar o site que você quer raspar. No README você encontra também informações valiosas como dicas e o que fazer em alguns casos de erros.
Outras dicas que eu acho legais são:
- Crie sempre uma branch no seu fork do projeto, assim você pode trabalhar em coisas diferentes localmente e sua branch principal (
main) estará em um estado sempre parecido com a do repositório do projeto; - Nessa página do Wiki você encontra o código da cidade no IBGE, informação obrigatória na adição de um spider (será usada no campo
TERRITORY_ID); - Atenção aos padrões de nomes: as classes devem seguir o padrão
<SiglaDoEstado><NomeDaCidade>Spidere o nome do arquivosigladoestado_nomedacidade.py. Sim, o padrão de maiúsculas e minúsculas deve ser seguido; - Ao preparar um pull request, certifique-se de que você rodou o spider todo e sem erros pelo menos uma vez na sua máquina. Isso ajuda bastante ao ter spiders confiáveis no repositório e diminui a carga de trabalho dos mantenedores do projeto;
- Ainda sobre criar um novo pull request, adicione uma boa descrição: qual a cidade e estado e informações relevantes para os mantenedores. É legal ter o comando de execução também; :)
- Se você quiser exportar os dados do seu spider local, pode executá-lo com um
cd data_collection && scrapy crawl <nome do seu spider> -o diarios.csv"; - Além da aba de inspeção, as ferramentas da pessoa desenvolvedora inclusa nos navegadores também costumam a ter a aba de Rede (Network). Lá você pode ver quais requisições foram disparadas ao clicar em um botão, por exemplo. Isso pode ser útil ao explorar um novo site.
É isso aí!#

Espero que esse texto tenha te ajudado a começar a contribuir para esse projeto tão importante para o Brasil. Boa sorte com as raspagens e muito bem-vindos ao Querido Diário!